
Multi-modal Knowledge Distillation-based Human Trajectory Forecasting
– Published Date : 2025.06.11
– Category : Human Pose
– Place of publication : IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2025
Abstract:
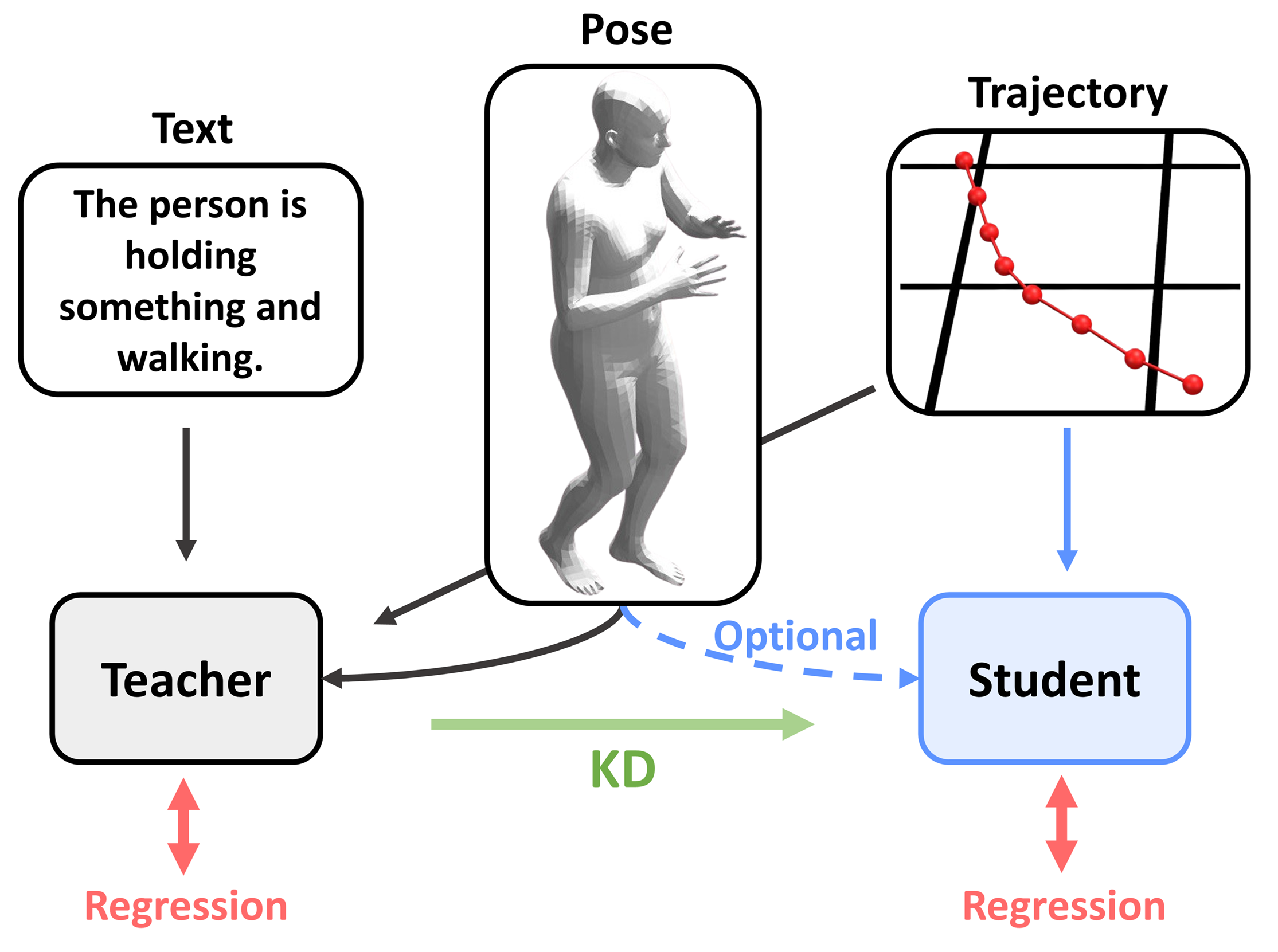
Abstract: Pedestrian trajectory forecasting is crucial in various applications such as autonomous driving and mobile robot navigation. Their camera-based visual features enable the extraction of additional modalities (human pose, text) which enhance prediction accuracy. We focus on pedestrian motion prediction to fully utilize the rich, dynamic visual features of pedestrians. Indeed, we find that textual descriptions play a crucial role in integrating additional modalities into a unified understanding. However, online extraction of text requires an use of VLM, which may not be feasible for resource-constrained systems. To address this challenge, we propose a multi-modal knowledge distillation framework: a student model with limited modality is distilled from a teacher model trained with full range of modalities. The comprehensive knowledge of a teacher model trained with trajectory, human pose, and text is distilled into a student model using only trajectory or human pose as a sole supplement. We validate our generalizable framework with two state-of-the-art models across three datasets on both ego-view (JRDB, SIT) and BEV-view (ETH/UCY) setups. For the SIT dataset, we utilize VLM to generate captions to compensate for the lack of text annotations. Distilled student models show consistent improvement in all prediction metrics for both full and instantaneous observations.



